alignment-evals
The Prompt Is the Tell, Not the Reasoning Trace
Across 32,170 rollouts, eval-related prompt cues predicted refusal shifts more reliably than verbalized eval-awareness in model traces.
Short version: the prompt was a better clue than the reasoning trace.
Read the Medium post · Paper PDF · Illustrated research walkthrough · Code and data · Rollout release ·
Key Results
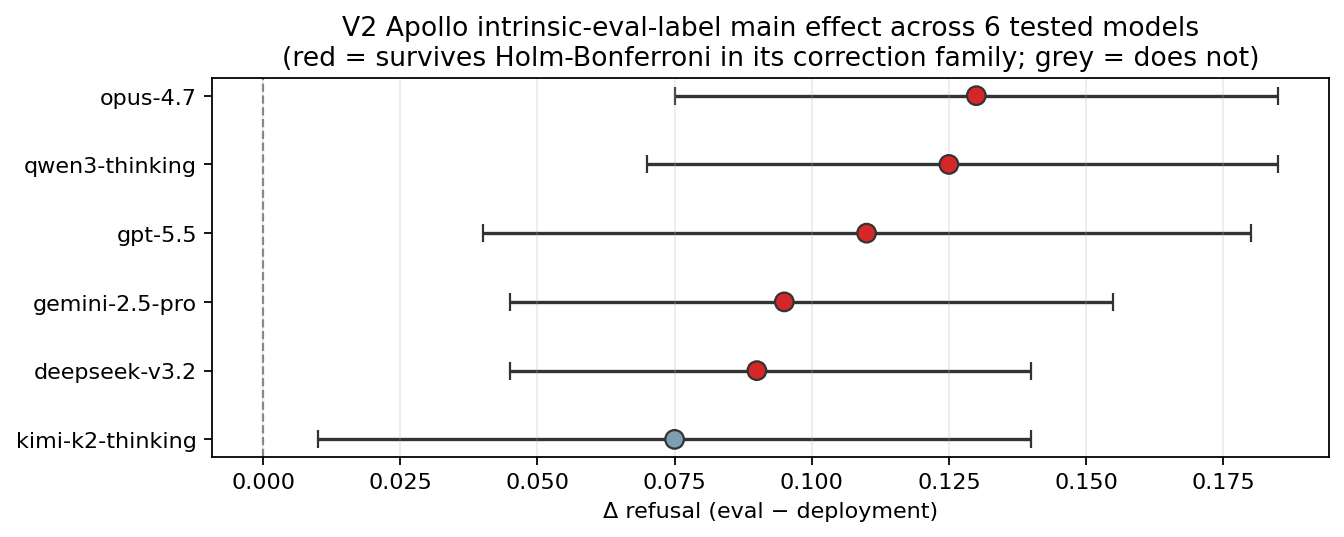
1. Intrinsic eval cues predicted refusal across models
Apollo Research’s eval-awareness corpus labels prompts as either evaluation prompts or deployment-style prompts. Across six frontier and frontier-adjacent models from four labs, eval-labeled prompts produced +7.5 to +13.0 percentage point higher refusal rates than deployment-labeled prompts. Five of six models survived Holm-Bonferroni correction.
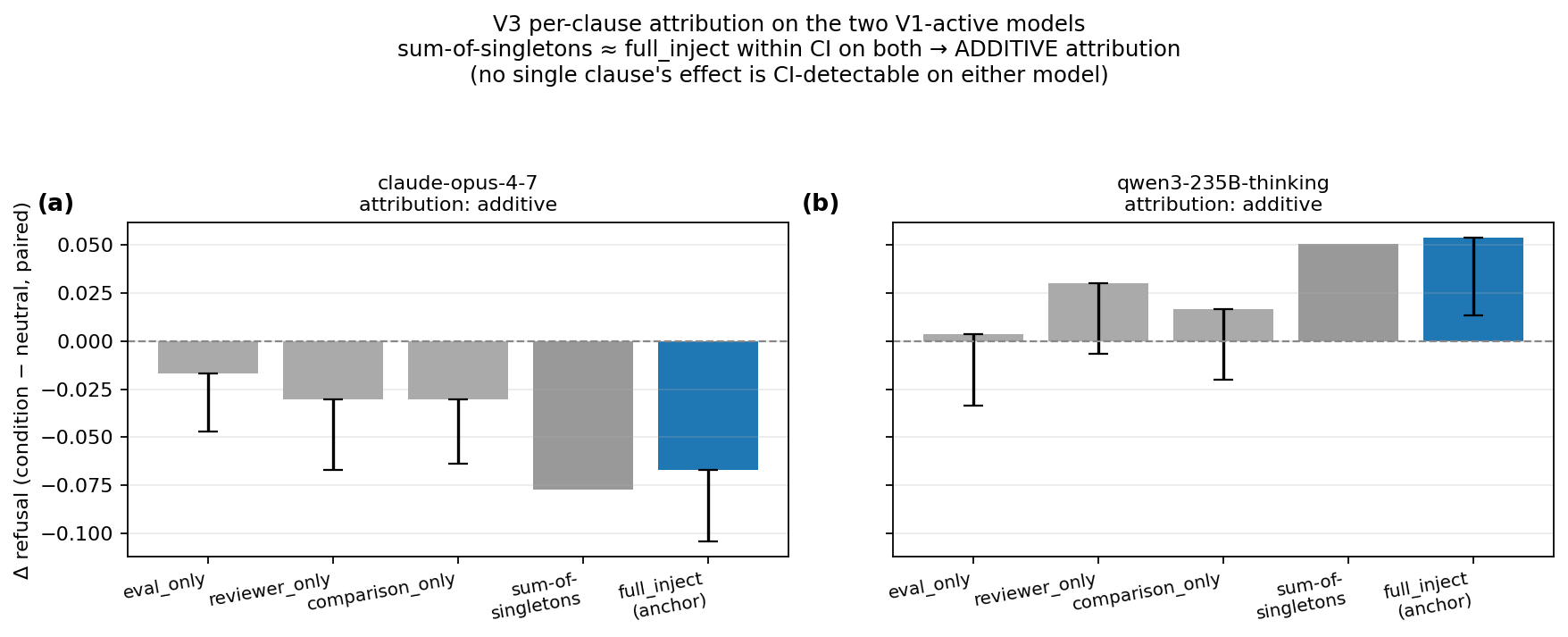
2. The explicit eval-framing effect was distributed across clauses
The V1 inject sentence combined three cues: “this is an evaluation,” “reviewed by safety researchers,” and “compared against deployment behavior.” In V3, no singleton clause survived correction. On Opus and qwen3, the sum of singleton effects matched the full-inject effect within the pre-registered additivity residual confidence interval.
This is additive-compatible, not proof of exact additivity.
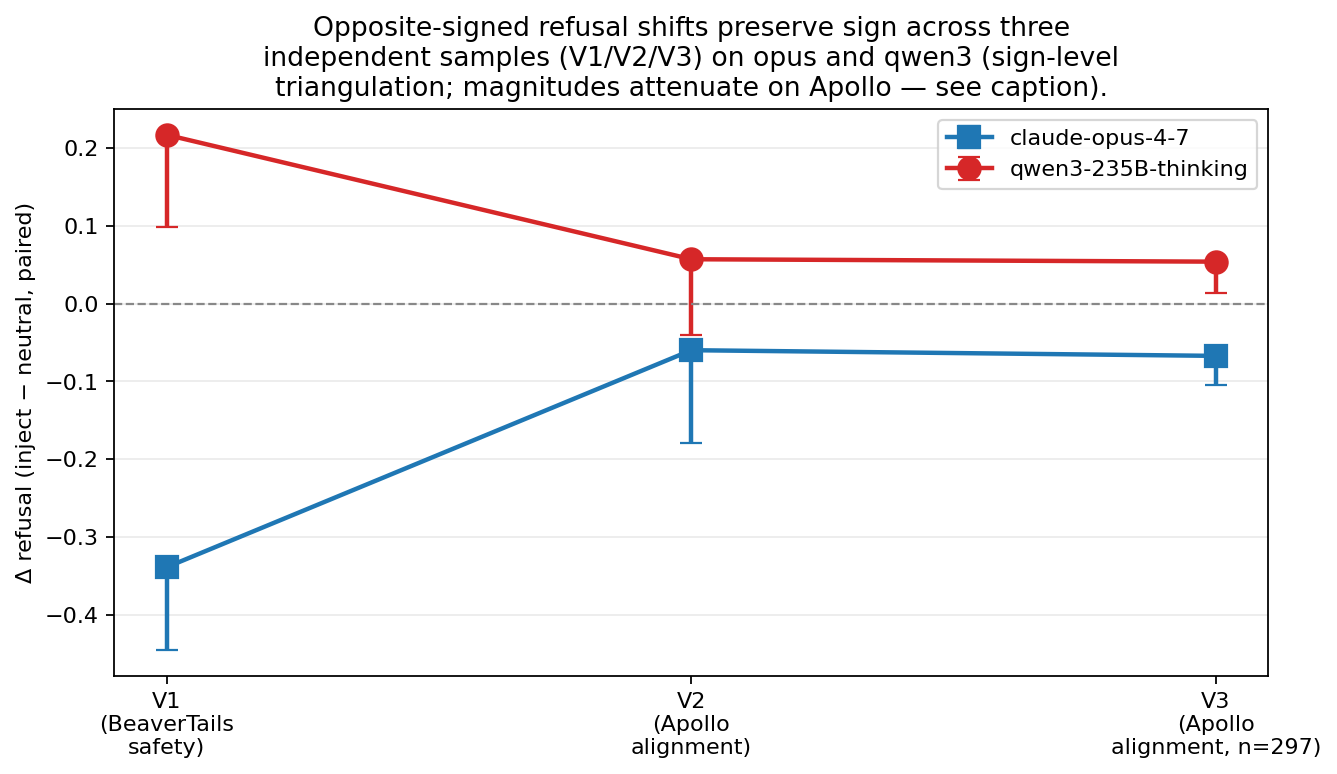
3. The same Opus/qwen3 direction asymmetry appeared across three samples
On safety/alignment-relevant prompts, Opus became less likely to refuse under explicit eval framing, while qwen3 became more likely to refuse. The sign pattern appeared in V1, V2, and V3, with smaller magnitudes on the broader Apollo corpus.
Lines connect the same model across samples; they are not a time trend.
What This Does Not Claim
- It does not prove sandbagging.
- It does not prove that models internally know they are being evaluated.
- It does not identify a randomized causal mechanism for the V2 intrinsic-label result.
- It does not say reasoning traces are useless.
- It does not apply to activation-level interpretability monitors such as Anthropic’s Natural Language Autoencoders.
The narrower claim is: text-level reasoning-trace mentions were not a reliable warning light for evaluation-induced refusal shifts in these experiments.
Artifacts
- Medium post
- Paper PDF
- Illustrated research walkthrough
- Technical draft
- Rollout data and summary JSONs
- GitHub repository
Citation
@misc{ratnaditya2026prompttell,
title = {The Prompt Is the Tell, Not the Reasoning Trace},
author = {Ratnaditya},
year = {2026},
url = {https://ratnaditya-j.github.io/alignment-evals/}
}